
Sean Perry
- @Sean
- | He/Him/His
Hello everyone!
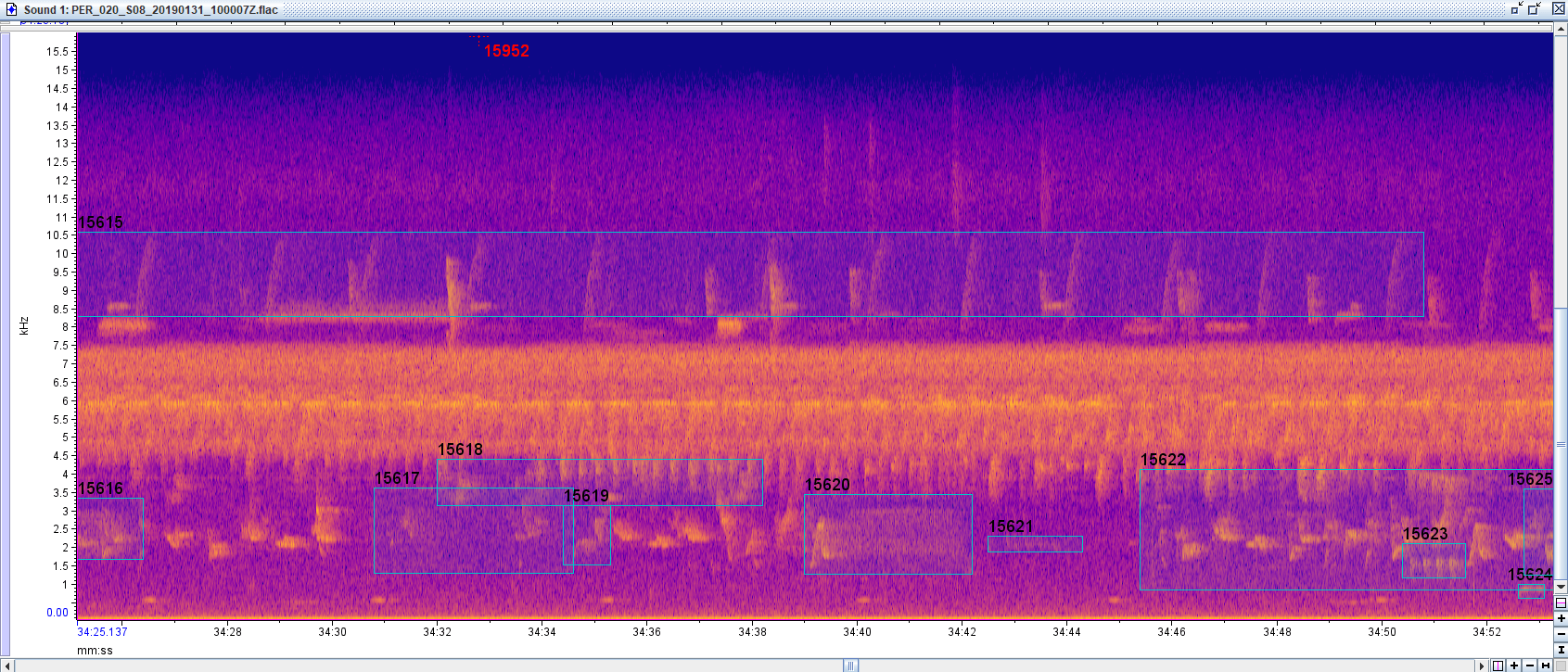
I am part of a team on developing CNNs to detect species in the Peruvian Amazon from soundscapes. We are having trouble finding a ground truth dataset for the region to test our model against. We have been trying to use “A collection of fully-annotated soundscape recordings from the Southwestern Amazon Basin” (https://zenodo.org/record/7079124#.Y7iis-xudhE) which seems to be the best publicly available strongly labeled ground truth from the region. However, we think there are a few errors in the labeling leading to our models having poorer results than they might. For instance, in the screenshot below, there seems to be an unlabeled species between 34:38 and 34:30 from 1 to 4 hz (and repeated again at 34:35 to 34:38) that is labeled in annotations 15616 and 15622. We have noticed a handful of what we think are these errors in the dataset, but we don’t necessarily have the expertise to know for sure. Has anyone used this data in training/testing and if so what are your thoughts on this data?
Thank you for your time!
Sean Perry
3 October 2023 10:47pm
Hi Sean!
Wanted to just mention that Arbimon, Rainforest Connection's ecoacoustic platform, has a number of projects in Peru (here, here, & others, if you search by keyword 'peru'). We have some existing CNNs for that region (mostly from Ecuador & Brazil, but there is likely species overlap). Do feel free to DM me here or email me (carly@rfcx.org) and I'm happy to talk about collaborating!
-Carly




3 October 2023 10:50pm
Also tagging @NickGardner who works on a similar project! (detecting birds from audio in Peruvian flooded forests)

Nick Gardner
University of Florida (UF)



8 October 2023 4:49pm
Interesting!
Hi Sean, sounds like an excellent project. Definitely talk with the Arbimon folks! As @carlybatist said, I am working with birds in the Peruvian Amazon, but in Loreto. Definitely would like to hear more about your project. As for this labelling issue here, definitely looks like an error. I have not used this dataset, now I'm curious. To be honest, some questionable labelling in that file in general. Bounding boxes can be very subjective...

31 August 2024 10:08pm
Hi Sean!
I was the one who annotated these recordings and this is definitely a mistake- that song is a Hauxwell's Thrush; it's annotated correctly with 15622 but not with 15616 (that's the same species as 15620). I'm currently in the field and don't have the ability to fix it right now, but should be able to later this month. If you have more of these, please send them to me (wah63@cornell.edu) and I'll correct any errors and upload a version 2. Same for you @NickGardner - I'm very happy to chat about any labeling decisions and correct mistakes or inconsistencies where applicable. Some were intentional/tossup decisions because of the subjective nature of manual bounding boxes, as you note, and some of them are obvious mistakes like the example Sean found, which can happen for a ton of reasons, despite my efforts to reduce or eliminate them. For context, I did the data collection, annotation, etc of this project essentially by myself when I was an undergrad, and so I guarantee there are some other similar errors in there, and, well, there is a reason that there haven't been many similar datasets made in this system! Especially at the time I did these (2019), there just wasn't an established standard for many of these decisions, and I just did the best I could. My main goal was just getting *something* from these systems out there, fully transparent and free, so that people like you could have more to work with. Ironically, these sort of human errors are exactly why the tools you're working on are so important, even though the fear of committing them probably contributes to the scarcity of similar datasets. Hopefully we will eventually be able to eliminate this kind of thing with better automated processes, but in the meantime, yes, please send me everything you found and we can correct them.
Thanks so much for using my dataset and looking at it closely enough to find mistakes - together we can make it better and more useful for future users :)
Best,
Alec
Carly Batist